
درک نحوه استفاده از فایل robots.txt برای هر استراتژی سئو وب سایت حیاتی است. اشتباهات در این فایل می تواند بر نحوه خزش وب سایت شما و ظاهر صفحات شما در جستجو تأثیر بگذارد. از سوی دیگر، درست کردن آن می تواند کارایی خزش را بهبود بخشد و مشکلات خزش را کاهش دهد.
گوگل اخیراً صاحبان وب سایت را در مورد اهمیت استفاده از robots.txt برای مسدود کردن URL های غیر ضروری یادآوری کرده است.
این موارد شامل صفحات افزودن به سبد خرید، ورود به سیستم یا پرداخت می شود. اما سوال اینجاست که چگونه از آن به درستی استفاده کنیم؟
در این مقاله، ما شما را در هر نکته ظریف نحوه انجام این کار راهنمایی خواهیم کرد.
فایل robots.txt چیست؟
فایل robots.txt یک فایل متنی ساده است که در دایرکتوری اصلی سایت شما قرار دارد و به خزنده ها می گوید چه چیزی باید خزیده شود.
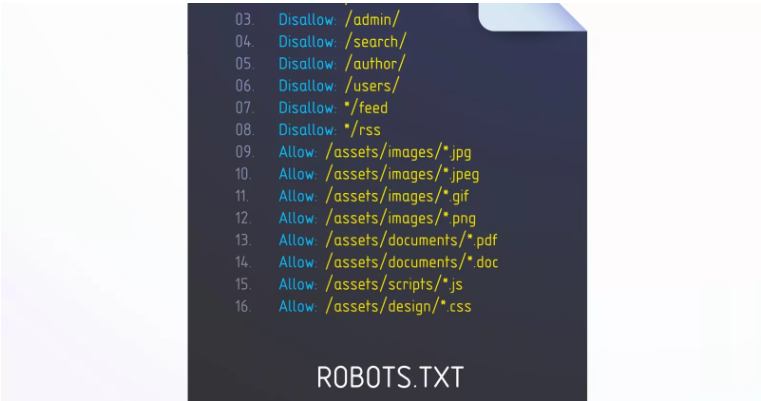
جدول زیر یک مرجع سریع برای دستورالعمل های کلیدی robots.txt را ارائه می دهد.

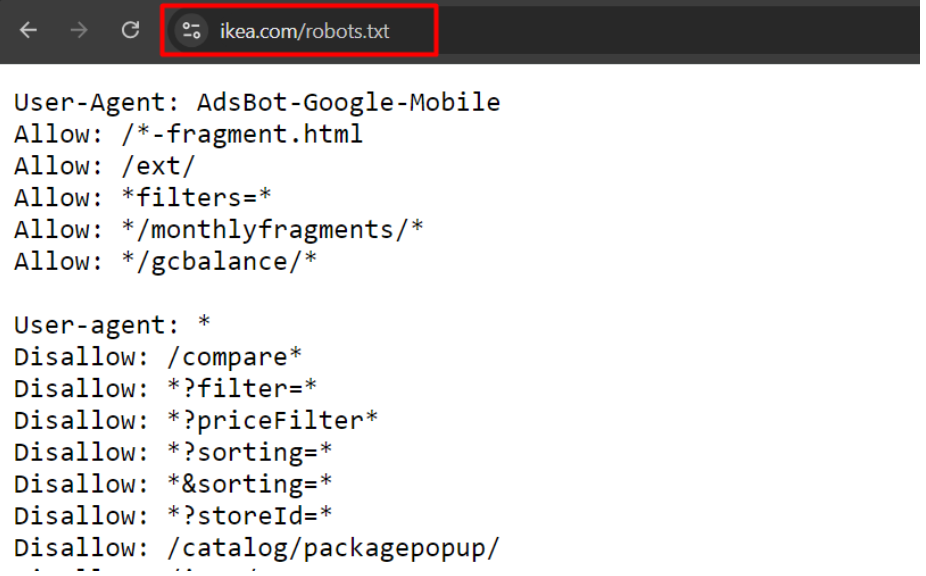
این یک مثال از فایل robots.txt سایت ikea.com است که حاوی قوانین متعدد است.
توجه داشته باشید که فایل robots.txt از عبارات منظم کامل پشتیبانی نمیکند و تنها از دو کاراکتر وحشی (wildcard) استفاده میکند:
- ستاره (*): این کاراکتر، صفر یا تعداد نامحدودی از کاراکترهای متوالی را تطبیق میدهد. به عبارت سادهتر، ستاره به معنای “هر چیزی” است و میتواند برای تطبیق هر رشتهای از کاراکترها استفاده شود.
- علامت دلار ($):درفایلrobots.txtعلامت دلار($) در فایل robots.txt به عنوان یک کاراکتر وحشی (wildcard) استفاده میشود تا نشان دهد یک الگوی خاص باید دقیقاً در انتهای یک URL قرار داشته باشد.
همچنین توجه داشته باشید که قوانین این فایل به حروف بزرگ و کوچک حساس هستند. به عنوان مثال، عبارت “filter=” با “Filter=” برابر نیست.
ترتیب تقدم در فایل robots.txt
هنگام تنظیم یک فایل robots.txt، دانستن ترتیبی که موتورهای جستجو برای تصمیم گیری در مورد اعمال قوانین در صورت وجود قوانین متناقض استفاده می کنند، مهم است.
آنها از این دو قانون کلیدی پیروی میکنند:
1_مختصترین قاعده:
قاعده ای که با بیشترین تعداد کاراکتر در URL مطابقت داشته باشد، اعمال خواهد شد. برای مثال:
User-agent: *
Disallow: /downloads/
Allow: /downloads/free/در این حالت، قانون “Allow: /downloads/free/” خاصتر از “Disallow: /downloads/” است زیرا به یک زیر شاخه اشاره میکند.
گوگل اجازه خزیدن زیر پوشه “/downloads/free/” را میدهد اما همه چیز زیر “/downloads/” را مسدود میکند.
2_کمترین قانون محدودکننده
وقتی چندین قانون به یک اندازه خاص باشند، برای مثال:
User-agent: *
Disallow: /downloads/
Allow: /downloads/گوگل همیشه سعی میکند کمترین محدودیت را اعمال کند. در این مورد خاص، از آنجایی که دو دستور متناقض داریم (یکی اجازه دسترسی میدهد و دیگری ممنوع میکند)، گوگل دستوری را انتخاب میکند که به رباتهای جستجو اجازه میدهد تا به پوشه /downloads/ دسترسی داشته باشند.
چرا فایل robots.txt در سئو مهم است؟
مسدود کردن صفحات غیر مهم با robots.txt به Googlebot کمک می کند تا بودجه خزش خود را بر روی قسمت های ارزشمند وب سایت و خزیدن صفحات جدید متمرکز کند. همچنین به موتورهای جستجو کمک می کند تا قدرت محاسباتی را ذخیره کنند و به پایداری بهتر کمک کنند.
تصور کنید که یک فروشگاه آنلاین با صدها هزار صفحه دارید. بخش هایی از وب سایت ها مانند صفحات فیلتر شده وجود دارد که ممکن است تعداد نامحدودی نسخه داشته باشند.
این صفحات ارزش منحصر به فردی ندارند، اساساً حاوی محتوای تکراری هستند و ممکن است فضای خزش نامحدودی ایجاد کنند، در نتیجه منابع سرور و Googlebot را هدر می دهند.
در اینجا است که robots.txt وارد عمل می شود و از خزیدن ربات های موتور جستجو در این صفحات جلوگیری می کند.
اگر این کار را نکنید، گوگل ممکن است سعی کند تعداد نامحدودی از URL ها را با مقادیر پارامتر جستجوی متفاوت (حتی غیر موجود) بخزد، که باعث ایجاد پیک ها و هدر رفتن بودجه خزش می شود.
چه زمانی از فایل robots.txt استفاده کنیم؟
- URL هایی که حاوی پارامترهای پرس و جو هستند:
- مانند جستجوی داخلی.
- URL های پیمایش وجهی ایجاد شده توسط گزینه های فیلتر یا مرتب سازی اگر بخشی از ساختار URL و استراتژی سئو نباشند.
- URL های عملی مانند افزودن به لیست علاقه مندی ها یا افزودن به سبد خرید.
- بخش های خصوصی وب سایت، مانند صفحات ورود.
- فایل های جاوا اسکریپت مرتبط با محتوای وب سایت یا رندرینگ نیستند، مانند اسکریپت های ردیابی.
- مسدود کردن اسکرپرها و چت بات های هوش مصنوعی برای جلوگیری از استفاده از محتوای شما برای اهداف آموزشی آنها.
بسیار خوب، بیایید با مثالهای عملی بررسی کنیم که چگونه میتوانید از فایل robots.txt در هر یک از موارد ذکر شده استفاده کنید.
1_مسدود کردن صفحات جستجوی داخلی
اولین و مهمترین قدم، مسدود کردن URL های جستجوی داخلی از خزیده شدن توسط گوگل و سایر موتورهای جستجو است، زیرا تقریباً هر وبسایتی دارای عملکرد جستجوی داخلی است.
در وبسایتهای وردپرس، معمولاً یک پارامتر “s” وجود دارد و URL به شکل زیر است:
https://www.example.com/?s=googleگری ایلیس از گوگل بارها هشدار داده است که URL های “عملی” را مسدود کنید، زیرا ممکن است باعث شود Googlebot به طور نامحدود آنها را بخزد، حتی URL های غیر موجود با ترکیبهای مختلف.
در اینجا قانون را میتوانید در فایل robots.txt خود استفاده کنید تا از خزیدن چنین URL هایی جلوگیری شود:
User-agent: *
Disallow: *s=*خط User-agent: * مشخص میکند که این قانون برای همه خزندههای وب، از جمله Googlebot، Bingbot و غیره اعمال میشود.
خط Disallow: *s=* به همه خزندهها میگوید که URL هایی را که حاوی پارامتر پرس و جو “s=” هستند، خزیده نشود. کاراکتر وحشی “*” به این معنی است که میتواند با هر دنبالهای از کاراکترها قبل یا بعد از “s=” مطابقت داشته باشد. با این حال، با URL هایی که دارای “S” بزرگ مانند “/?S=” هستند، مطابقت نخواهد داشت زیرا به حروف کوچک و بزرگ حساس است.
در اینجا مثالی از یک وبسایت آورده شده است که پس از مسدود کردن URLهای جستجوی داخلی غیر موجود از طریق robots.txt، توانست به طور چشمگیری میزان خزش آنها را کاهش دهد.
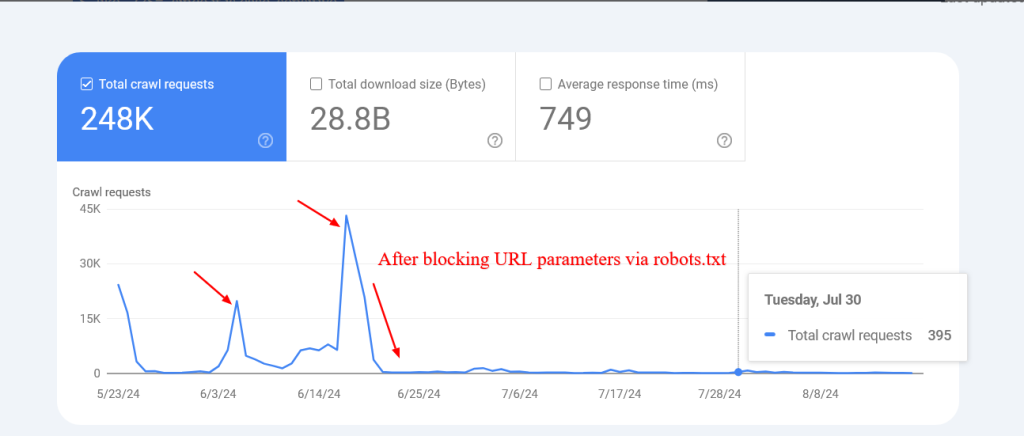
توجه داشته باشید که گوگل ممکن است این صفحات مسدود شده را ایندکس کند، اما نگران نباشید زیرا با گذشت زمان حذف خواهند شد.
2. مسدود کردن URL های پیمایش وجهی
پیمایش وجهی (Faceted Navigation) بخش جدایی ناپذیر هر وبسایت تجارت الکترونیک است. مواردی وجود دارد که پیمایش وجهی بخشی از استراتژی سئو است و برای رتبهبندی در جستجوی عمومی محصولات هدفگذاری شده است.
به عنوان مثال، زالاندو از URL های پیمایش وجهی برای گزینههای رنگ استفاده میکند تا برای کلمات کلیدی عمومی محصول مانند “تیشرت خاکستری” رتبهبندی شود.
با این حال، در اکثر موارد، اینطور نیست و پارامترهای فیلتر صرفاً برای فیلتر کردن محصولات استفاده میشوند و دهها صفحه با محتوای تکراری ایجاد میکنند.
از نظر فنی، این پارامترها با پارامترهای جستجوی داخلی متفاوت نیستند، با این تفاوت که ممکن است چندین پارامتر وجود داشته باشد. شما باید مطمئن شوید که همه آنها را مسدود میکنید.
به عنوان مثال، اگر فیلترهایی با پارامترهای زیر دارید: “sortby”، “color” و “price”، میتوانید از این مجموعه قوانین استفاده کنید:
User-agent: *
Disallow: *sortby=*
Disallow: *color=*
Disallow: *price=*بر اساس مورد خاص شما، ممکن است پارامترهای بیشتری وجود داشته باشد و شما نیاز داشته باشید که همه آنها را اضافه کنید.
پارامترهای UTM چگونهاند؟
پارامترهای UTM برای اهداف ردیابی استفاده میشوند. همانطور که جان مولر در پست Reddit خود بیان کرد، نیازی نیست نگران پارامترهای URL باشید که به صفحات شما از خارج لینک میدهند.
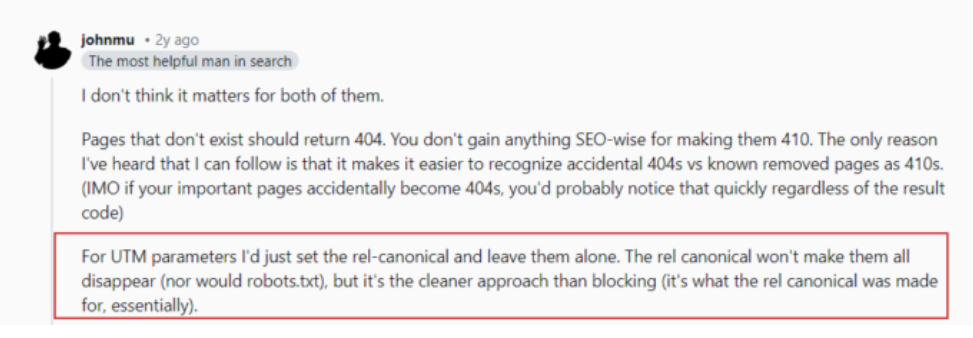
فقط مطمئن شوید که هر پارامتر تصادفی که به صورت داخلی استفاده میکنید را مسدود کنید و از لینک دادن داخلی به آن صفحات خودداری کنید. برای مثال، از صفحات مقاله خود به صفحه جستجو با یک عبارت جستجو در URL مانند “https://www.example.com/?s=google” لینک ندهید.
3. مسدود کردن آدرسهای PDF
فرض کنید تعداد زیادی سند PDF دارید، مانند راهنماهای محصول، بروشورها یا مقالات قابل دانلود، و نمیخواهید این اسناد توسط موتورهای جستجو ایندکس شوند.
این یک قانون ساده robots.txt است که از دسترسی ربات های موتور جستجو به آن اسناد جلوگیری می کند:
User-agent: *
Disallow: /*.pdf$**خط “Disallow: /*.pdf$” به خزنده ها می گوید که هیچ URLی که با .pdf ختم می شود را خزیده نشود.** **با استفاده از /*، این قانون با هر مسیری در وب سایت مطابقت دارد. در نتیجه، هر URL که با .pdf ختم شود از خزیدن مسدود خواهد شد.** **اگر شما یک وب سایت وردپرس دارید و می خواهید PDF ها را از دایرکتوری آپلود که از طریق CMS آپلود می کنید، مسدود کنید، می توانید از قانون زیر استفاده کنید:**
User-agent: *
Disallow: /wp-content/uploads/*.pdf$
Allow: /wp-content/uploads/2024/09/allowed-document.pdf$همانطور که مشاهده میکنید، ما در اینجا قوانین متناقضی داریم.
در صورت وجود قوانین متناقض، قانون **خاصتر** اولویت دارد، به این معنی که خط آخر تضمین میکند که فقط فایل خاصی که در پوشه “wp-content/uploads/2024/09/allowed-document.pdf” قرار دارد، مجاز به خزیدن است.
4_مسدود کردن یک دایرکتوری
فرض کنید یک نقطه پایانی API دارید که از طریق فرم دادههای خود را ارسال میکنید. احتمالاً فرم شما دارای یک ویژگی action مانند action=”/form/submissions/” است.
مشکل این است که گوگل سعی میکند URL /form/submissions/ را خزیده کند، که احتمالاً نمیخواهید. میتوانید از خزیده شدن این URLها با این قانون جلوگیری کنید:
User-agent: *
Disallow: /form/دایرکتوری خاصی را در قانون Disallow مشخص میکنید، به خزاندهها میگویید که از خزیدن تمام صفحات زیر آن دایرکتوری اجتناب کنند و دیگر نیازی به استفاده از کاراکتر (*) به عنوان کاراکتر جایگزین، مانند “/form/*” ندارید. توجه داشته باشید که همیشه باید مسیرهای نسبی را مشخص کنید و هرگز از URLهای مطلق مانند “https://www.example.com/form/” برای دستورات Disallow و Allow استفاده نکنید. برای جلوگیری از قوانین نادرست محتاط باشید. به عنوان مثال، استفاده از /form بدون اسلش انتهایی، صفحهای مانند /form-design-examples/ را نیز مطابقت میدهد، که ممکن است صفحهای در وبلاگ شما باشد که میخواهید ایندکس شود.
5_مسدود کردن URLهای حساب کاربری
اگر یک وبسایت تجارت الکترونیک دارید، احتمالاً دایرکتوریهایی دارید که با “/myaccount/” شروع میشوند، مانند “/myaccount/orders/” یا “/myaccount/profile/”.
با اینکه صفحه اصلی “/myaccount/” یک صفحه ورود به سیستم است که میخواهید توسط کاربران در جستجو ایندکس و پیدا شود، ممکن است بخواهید از خزیدن زیرصفحات توسط Googlebot جلوگیری کنید.
میتوانید از قانون Disallow در ترکیب با قانون Allow برای مسدود کردن همه چیز زیر دایرکتوری “/myaccount/” (به جز صفحه /myaccount/) استفاده کنید.
User-agent: *
Disallow: /myaccount/
Allow: /myaccount/$و باز هم، از آنجایی که گوگل از خاصترین قانون استفاده میکند، همه چیز زیر دایرکتوری /myaccount/ را مسدود میکند اما فقط به صفحه /myaccount/ اجازه خزیدن میدهد.
در اینجا یک مورد استفاده دیگر از ترکیب قوانین Disallow و Allow وجود دارد: در صورتی که جستجوی خود را در زیر دایرکتوری /search/ داشته باشید و بخواهید آن پیدا و ایندکس شود اما URLهای جستجوی واقعی را مسدود کنید.
User-agent: *
Disallow: /search/
Allow: /search/$6. مسدود کردن فایلهای جاوا اسکریپت غیرمرتبط با رندر
هر وبسایت از جاوا اسکریپت استفاده میکند و بسیاری از این اسکریپتها به رندر کردن محتوا مرتبط نیستند، مانند اسکریپتهای ردیابی یا آنهایی که برای بارگذاری AdSense استفاده میشوند.
Googlebot میتواند بدون این اسکریپتها، محتوای وبسایت را خزیده و رندر کند. بنابراین، مسدود کردن آنها ایمن و توصیه میشود، زیرا باعث صرفهجویی در درخواستها و منابع برای دریافت و تجزیه آنها میشود.
در زیر یک خط نمونه وجود دارد که جاوا اسکریپت نمونه را که حاوی پیکسلهای ردیابی است، مسدود میکند:
User-agent: *
Disallow: /assets/js/pixels.js7_مسدود کردن رباتهای چت و اسکراپرهای هوش مصنوعی
بسیاری از ناشران نگران هستند که محتوای آنها بدون رضایت آنها برای آموزش مدلهای هوش مصنوعی به طور ناعادلانه استفاده میشود و میخواهند از این امر جلوگیری کنند.
#ai chatbots
User-agent: GPTBot
User-agent: ChatGPT-User
User-agent: Claude-Web
User-agent: ClaudeBot
User-agent: anthropic-ai
User-agent: cohere-ai
User-agent: Bytespider
User-agent: Google-Extended
User-Agent: PerplexityBot
User-agent: Applebot-Extended
User-agent: Diffbot
User-agent: PerplexityBot
Disallow: /#scrapers
User-agent: Scrapy
User-agent: magpie-crawler
User-agent: CCBot
User-Agent: omgili
User-Agent: omgilibot
User-agent: Node/simplecrawler
Disallow: /در اینجا، هر عامل کاربری به صورت جداگانه فهرست شده است و قانون Disallow: / به آن رباتها میگوید که هیچ بخشی از سایت را خزیده نشود. این کار علاوه بر جلوگیری از آموزش هوش مصنوعی بر روی محتوای شما، میتواند با کاهش خزیدن غیرضروری، بار سرور شما را کاهش دهد. برای ایدههایی در مورد اینکه کدام رباتها را مسدود کنید، ممکن است بخواهید فایلهای لاگ سرور خود را بررسی کنید تا ببینید کدام خزندهها سرورهای شما را تخلیه میکنند، و به یاد داشته باشید که robots.txt از دسترسی غیرمجاز جلوگیری نمیکند.
8_مشخص کردن URLهای نقشه سایت
درج URL نقشه سایت شما در فایل robots.txt به موتورهای جستجو کمک میکند تا به راحتی تمام صفحات مهم وبسایت شما را کشف کنند. این کار با افزودن یک خط خاص که به مکان نقشه سایت شما اشاره میکند انجام میشود و میتوانید چندین نقشه سایت را مشخص کنید، هر کدام در یک خط جداگانه.
Sitemap: https://www.example.com/sitemap/articles.xml
Sitemap: https://www.example.com/sitemap/news.xml
Sitemap: https://www.example.com/sitemap/video.xmlبرخلاف قوانین Allow یا Disallow که فقط یک مسیر نسبی را مجاز میکنند، دستور Sitemap نیاز به یک URL کامل و مطلق برای نشان دادن مکان نقشه سایت دارد. اطمینان حاصل کنید که URLهای نقشه سایت در دسترس موتورهای جستجو هستند و دارای نحو مناسب برای جلوگیری از خطا هستند.
9. چه زمانی از Crawl-Delay استفاده کنیم
دستور crawl-delay در robots.txt تعداد ثانیههایی را مشخص میکند که یک ربات باید قبل از خزیدن صفحه بعدی منتظر بماند. در حالی که Googlebot دستور crawl-delay را تشخیص نمیدهد، ممکن است رباتهای دیگر از آن پیروی کنند.
این به جلوگیری از اضافه بار سرور با کنترل میزان دفعات خزیدن رباتها در سایت شما کمک میکند.
به عنوان مثال، اگر میخواهید ClaudeBot محتوای شما را برای آموزش هوش مصنوعی خزیده کند اما میخواهید از اضافه بار سرور جلوگیری کنید، میتوانید یک تأخیر خزیدن را برای مدیریت فاصله بین درخواستها تنظیم کنید.
User-agent: ClaudeBot
Crawl-delay: 60این به عامل کاربری ClaudeBot دستور میدهد که بین درخواستها هنگام خزیدن وبسایت 60 ثانیه صبر کند. البته، ممکن است رباتهای هوش مصنوعی وجود داشته باشند که از دستورالعملهای تأخیر خزیدن پیروی نمیکنند. در این صورت، ممکن است نیاز به استفاده از یک فایروال وب برای محدود کردن سرعت آنها داشته باشید.
عیب یابی Robots.txt
پس از تهیه robots.txt، می توانید از این ابزارها برای عیب یابی استفاده کنید تا ببینید آیا نحو آن صحیح است یا اینکه به طور تصادفی URL مهمی را مسدود نکرده اید.
1. اعتبارسنج robots.txt کنسول جستجوی گوگل
پس از بهروزرسانی robots.txt، باید بررسی کنید که آیا حاوی خطایی است یا به طور تصادفی URLهایی را که میخواهید خزیده شوند، مانند منابع، تصاویر یا بخشهای وبسایت، مسدود میکند.
به Settings > robots.txt بروید و اعتبارسنج داخلی robots.txt را پیدا خواهید کرد. در زیر ویدیویی از نحوه دریافت و اعتبارسنجی robots.txt شما وجود دارد.
2_تجزیهکننده robots.txt گوگل
این تجزیهکننده تجزیهکننده رسمی robots.txt گوگل است که در Search Console استفاده میشود.
برای نصب و اجرای آن روی رایانه محلی خود به مهارتهای پیشرفته نیاز است. اما توصیه میشود که وقت بگذارید و آن را طبق دستورالعملهای موجود در آن صفحه انجام دهید زیرا میتوانید تغییرات خود را در فایل robots.txt قبل از آپلود به سرور خود مطابق با تجزیهکننده رسمی گوگل اعتبارسنجی کنید.
مدیریت متمرکز robots.txt
هر دامنه و زیرمجموعه باید robots.txt خاص خود را داشته باشد، زیرا Googlebot فایل robots.txt دامنه اصلی را برای یک زیرمجموعه تشخیص نمی دهد.
این امر زمانی که وب سایتی با ده ها زیرمجموعه دارید چالش هایی را ایجاد می کند، زیرا به این معنی است که شما باید چندین فایل robots.txt را به طور جداگانه نگهداری کنید.
با این حال، میزبانی یک فایل robots.txt در یک زیرمجموعه، مانند https://cdn.example.com/robots.txt، و تنظیم یک تغییر مسیر از https://www.example.com/robots.txt به آن امکان پذیر است.
شما می توانید برعکس عمل کنید و آن را فقط در زیر دامنه اصلی میزبانی کنید و از زیرمجموعه ها به دامنه اصلی هدایت کنید.
موتورهای جستجو با فایل هدایت شده همانطور رفتار می کنند که گویی در دامنه اصلی قرار دارد. این رویکرد به مدیریت متمرکز قوانین robots.txt برای هر دو دامنه اصلی و زیرمجموعههای شما اجازه میدهد.
این به کارآمدتر کردن به روز رسانی و نگهداری کمک می کند. در غیر این صورت، برای هر زیرمجموعه باید از یک فایل robots.txt جداگانه استفاده کنید.
نتیجه گیری
یک فایل robots.txt بهینه شده به درستی برای مدیریت بودجه خزیدن یک وبسایت بسیار مهم است. این تضمین میکند که موتورهای جستجو مانند Googlebot وقت خود را صرف صفحات ارزشمند میکنند و نه اینکه منابع خود را صرف موارد غیرضروری کنند.
از سوی دیگر، مسدود کردن رباتهای هوش مصنوعی و اسکراپرها با استفاده از robots.txt میتواند بار سرور را به میزان قابل توجهی کاهش دهد و منابع محاسباتی را ذخیره کند.
مطمئن شوید که همیشه تغییرات خود را اعتبارسنجی کنید تا از مشکلات غیرمنتظره خزیدن جلوگیری کنید.
با این حال، به یاد داشته باشید که در حالی که مسدود کردن منابع غیرمهم از طریق robots.txt ممکن است به افزایش کارایی خزیدن کمک کند، عوامل اصلی موثر بر بودجه خزیدن، محتوای باکیفیت و سرعت بارگذاری صفحه هستند.








